If you’d like to experience this methodology first-hand, try out Honcho Chat—an interface to your personal memory. Read more here!
Why Reasoning?
Traditional RAG systems treat memory as static storage—they retrieve what was explicitly said when semantically similar queries appear. Other solutions take an opinion for you on what’s important to store, whether through structured facts in databases or predefined knowledge graphs. Honcho takes a different approach: we extract all latent information by reasoning about everything, so it’s there when you need it. Our job is to produce the most robust reasoning possible—it’s your job as a developer to decide what’s relevant for your use case. We extract this latent information through formal logic. Formal logical reasoning is AI-native—LLMs perform the rigorous, compute-intensive thinking that humans struggle with, instantly and consistently. This unlocks insights that are only accessible by rigorously thinking about your data, generating new understanding that goes beyond simple recall.Formal Logic Framework
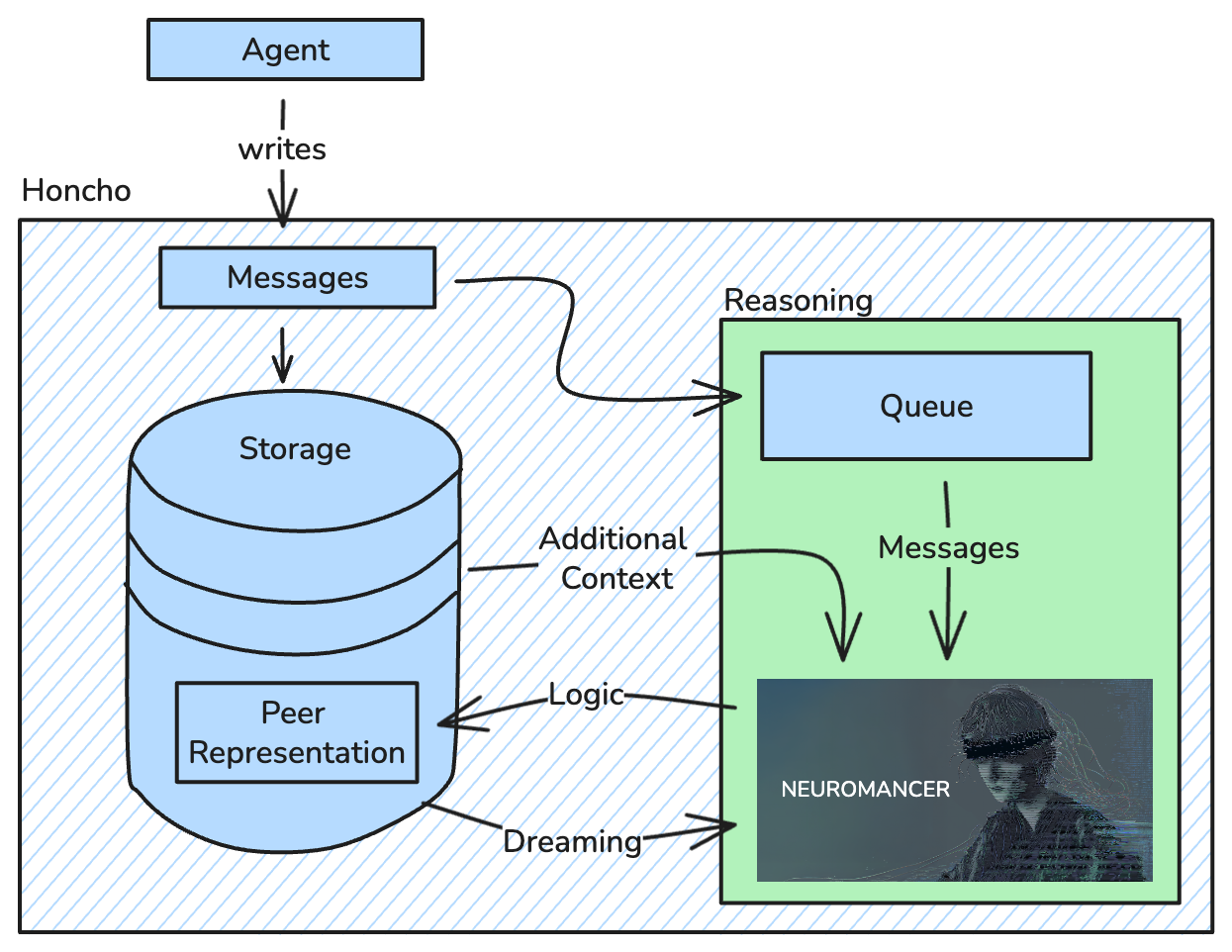
Honcho’s memory system is powered by custom models trained to perform formal logical reasoning. The system extracts what was explicitly stated, draws certain conclusions from those, identifies patterns across multiple conclusions, and infers the simplest explanations for behavior. Why formal logic specifically? LLMs are uniquely well-suited for this reasoning task—it’s well-represented in the pretraining data. LLMs can maintain consistent reasoning across thousands of conclusions without cognitive fatigue or belief resistance—which is extremely hard for humans to do reliably. The outputs are also composable, meaning logical conclusions can be stored, retrieved, and combined programmatically for dynamic context assembly. Here’s an example of a data structure the reasoning models generate:How It Works
When you write messages to Honcho, they’re stored immediately and enqueued for background processing. Reasoning asynchronously ensures fast writes while still providing rich reasoning capabilities. Messages are stored immediately without blocking, and session-based queues maintain chronological consistency so reasoning tasks affecting the same peer representation are always processed in order. The reasoning outputs—conclusions, summaries, peer cards—are stored as part of peer representations, indexed in vector collections for retrieval.